Research Interests
While I am broadly interested in topics related to programming languages (PL) and software engineering (SE), my main focus is on a new paradigm of program analysis that incorporates Bayesian reasoning. I have been working on it since my Ph.D study (see my thesis), and my research spans applications, languages, algorithms, and theories of Bayesian program analysis. My other research interests include optimizing domain-specific languages for program synthesis, artificial intelligence explainability, abstraction selection for conventional program analyses.
Bayesian Program Analysis
Bayesian program analysis incorporates probabilistic reasoning into program analysis, which allows handling uncertainties. This enables existing logic-based program analysis to quantify the confidence of its produced alarms, which can be ranked with the confidence. More importantly, it can enable program analysis to update the confidence by learning from information such as user feedback, informal information, and test runs. Around this paradigm, my group has developed multiple applications under it, and new algorithms and theories to support it, including:
- Applications: We have built program analysis augmented with uncertain information [OOPSLA'25a], fuzzing techniques guided by Bayesian program analysis [POPL'26a], and probabilistic fault localization [TSE'25].
- Abstraction Selection: Program abstraction controls the scalability and precision of program analysis by selecting appropriate levels of detail and representation. In the Bayesian setting, it also controls the learning ability of the system, which adds another layer of complexity. We have developed a data-driven offline learning approach [OOPSLA'24a] and a online search approach that is inspired by the counter-example guided abstraction refinement technique [OOPSLA'25b].
- Inference Algorithm: To Support efficient inference and learning, we have developed a novel probabilistic inference algorithm that exploits local structures in program analysis [ASE'25]. We have also developed a GPU-based pararell inference algorithm, which is currently under submission.
- Theory: We have developed a new theory which is a probabilistic extension to the famous abstract interpretation framework. It assigns confidence to analysis results and is currently conditionally accepted to PLDI'26.
Optimizing DSLs for Accelerating Program Synthesis
This project aims to accelerate syntax-guided program synthesis by automatically optimizing Domain-Specific Languages (DSLs) through a novel framework called AMaze [POPL'26b]. Because manually designing optimal DSLs is complex and often limits performance, AMaze iteratively refines them by identifying key program fragments that impact synthesis time. By leveraging a combination of dynamic programming and machine learning, the system accurately estimates synthesis costs, bypassing the need for computationally expensive direct execution. Evaluated across multiple domains on state-of-the-art synthesizers—including DryadSynth, Duet, Polygen, and EUsolver—AMaze successfully preserves language expressiveness while delivering up to a 4.35× speedup. We're currently working on extending AMaze to optimize DSLs for program generation with large langauge models.
Data-Driven Approaches for Abstract Selection in Traditional Program Analyses
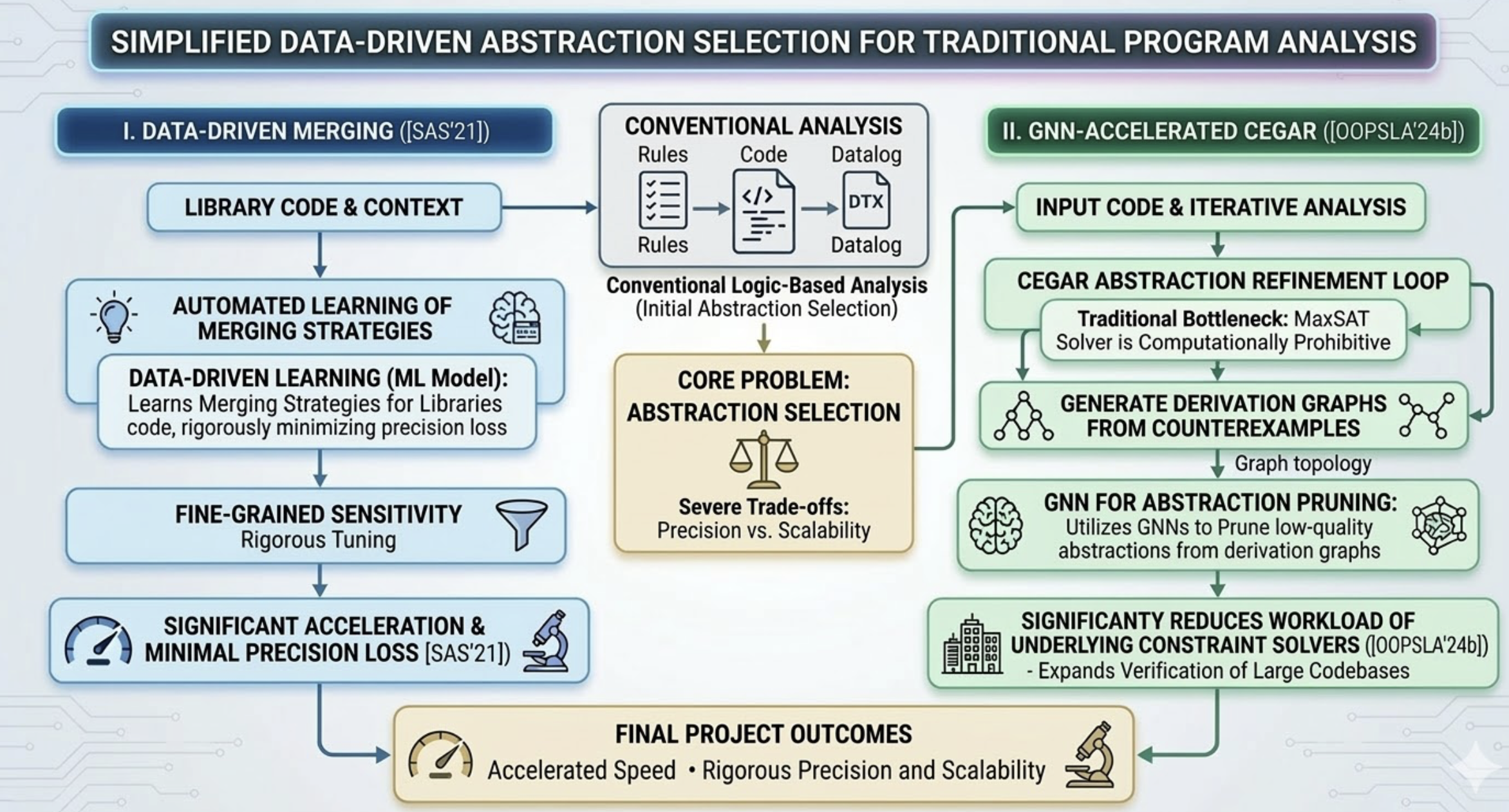
This project aims to optimize abstraction selection in conventional logic-based program analysis by overcoming severe trade-offs between precision and scalability. To enable fine-grained sensitivity tuning in purely logical frameworks like Datalog, the project introduces a data-driven technique that automatically learns optimal merging strategies for library code, significantly accelerating analysis while rigorously minimizing precision loss [SAS'21]. Furthermore, the project tackles the inherent scalability bottlenecks of counterexample-guided abstraction refinement (CEGAR) by integrating Graph Neural Networks (GNNs) [OOPSLA'24b]. By utilizing GNNs to prune low-quality abstractions from the topological structures of derivation graphs, this framework significantly reduces the workload of the underlying constraint solvers, expanding the horizon of large codebases that can be practically and rigorously verified.